
Llama를 한 번쯤은 로컬에서 구동해보고 싶었는데 이번에 Llama3.1 이 나오고 엄청 핫하길래 기회가 될 때 시도해 보기로 했다. 듣기로는 오픈소스는 여러 사람의 집단 지성으로 더 빨리 발전한다고도 함. 아무튼 Llama 를 사용하는 방법은 여러가지가 있는데 그 중 두가지를 시도 해봤다.
- Linux 환경에서 Llama3.1 model 돌리기
- 올라마 사용
당연하게도 올라마를 사용하는게 압도적으로 쉬움.
Linux 환경에서 시도한 내용
[Llama3.1] Windows 로컬 에서 AI 모델 사용하기 - Ubuntu 24.04
Llama3.1 모델을 처음 설치할때 Windows 에 설치 했다가 에러가 하도 많아서 그냥 Ubuntu 에서 실행하기로 했다.Ubuntu 설치는 이전에 올린 글 참조 24.04 버전 설치 https://bob-data.tistory.com/42 [Linux] Windows
bob-data.tistory.com
Ollama 는 뭘까? https://ollama.com/
쉽게 말해 라마 모델을 여러 환경 (Linux, Windows, macOS) 에서 사용하기 편하게 해주는 프레임워크라고 볼 수 있다. Linux 에 모델 설치해보면서 느꼈는데 진짜 쉬움.
올라마 설치 방법
올라마 홈페이지 https://ollama.com/ 에 접속해서 본인 PC 환경에 맞춰 설치하면 됨
Linux 는 아래 명령어 참조
curl -fsSL https://ollama.com/install.sh | sh
설치 끝나면 아래 같이 cmd 창에 설치 완료 글이 뜨고 ollama 를 입력하면 사용 가능한 명령어가 뜸. 이렇게 나오면 설치는 끝난거임.
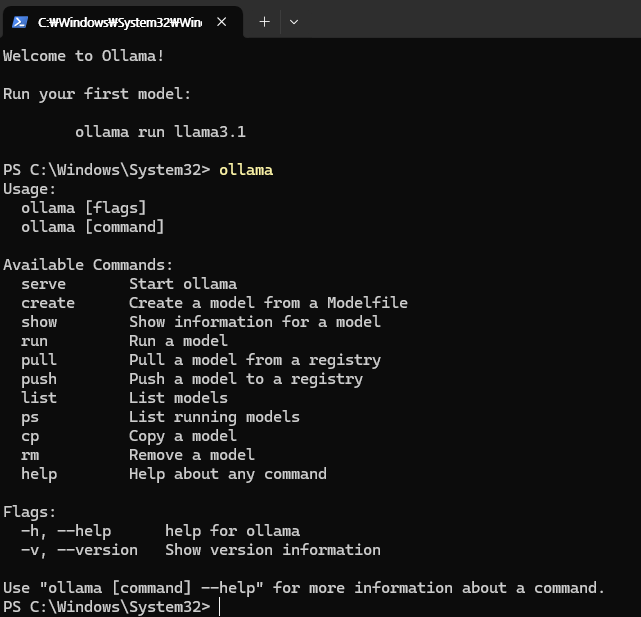
라마 모델 설치 및 실행
https://github.com/ollama/ollama 올라마 깃 페이지에 가면 실행 방법이 자세히 써 있다.
원하는 모델을 설치 한다.
ollama run llama3.1현재까지 올라마에서 설치 가능한 모델은 다음과 같다. ( https://ollama.com/library ) 다른 학습된 모델들도 받아서 사용할 수 있는데 비슷한 방법으로 fine tuning 을 할 예정이다. 학습된 모델들은 hugging face https://huggingface.co/models 여기서 받으면 됨. 모델도 많고 데이터 셋도 많아서. 활용하기에 정말 좋은 사이트임. 그리고 내가 만든 모델도 내 저장소에 push 할 수 있음.

*주의사항은 You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models. 라고 적혀 있다. Llama3.1 8B 를 사용하려면 최소 램 8GB 는 있어야 한다.
자 이제 라마 모델이 설치 되었다. 잘 설치 되었는지 확인하려면
ollama list // 모델 리스트를 보여준다설치가 완료되면 >>> 이 표시가 뜨게 되고 프롬프트 형식으로 질문을 할 수 있게 된다. 이렇게 해서 Llama 모델을 사용해도 된다. 그런데 한글은 지원을 안하다 보니 성능이 많이 떨어진다. 누가 허깅에 한국어 학습된 모델을 올려놨으니 그걸 사용해도 괜찮다.

REST API 요청
API 를 요청해서 사용할 수도 있다. ollama 를 실행 시켜놓고 이건 ollama serve 명령어를 사용 하면 된다. 그러면 서버가 실행되어 있게 되는데.
만약 이런 에러가 뜨면 ollma 가 이미 실행 중이니 실행중인 올라마를 종료해주고 다시 시도하면 된다. Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted.
Generate response
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt":"Why is the sky blue?"
}'Chat with a model
curl http://localhost:11434/api/chat -d '{
"model": "llama3.1",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'뭐 이렇게도 사용할 수 있다. 만약 학습할 내용이 있다면 langchain 모델을 쓰며 python 에 코드를 작성하고 실행 시키는 것도 괜찮아 보인다. 참고로 python, js 둘다 사용할 수 있다.
모델 커스터마이즈
hugging face 에서 모델 다운
올라마 깃에 있는 방법은 GGUF 모델을 커스터마이즈 하는 방법이다. 위에서 말한 hugging face https://huggingface.co/models 에서 GGUF 모델을 검색해서 다운 받으면 된다. 원하는 모델을 받아도 된다. 나는 https://huggingface.co/lmstudio-community/Meta-Llama-3.1-8B-Instruct-GGUF 이 모델을 받았다. Files and versions 탭에 들어가 원하는 것을 받으면 된다. Q1~Q8 의 의미는 숫자가 높을 수록 성능이 높은 모델이라고 생각하면 된다. 성능이 높을수록 높은 사양을 필요로 한다. 파일을 다운 받고 해당 위치를 기억해논다.
1. 파일 이름을 Modelfile 로 생성하면서 파일안에 위에서 다운 받은 모델을 경로를 넣어 줄 거다.
// Modelfile 생성
// 경로는 위에서 더운 받은 파일의 경로로 넣어준다.
echo "FROM ./vicuna-33b.Q4_0.gguf" > Modelfile
// 또한 Modelfile 안에 아래 내용을 입력해주면 요청하는 대로 글을 작성하게 된다.
# Define the template for the interaction
TEMPLATE """{{- if .System }}
<s>{{ .System }}</s>
{{- end }}
<s>Fan:
{{ .Prompt }}</s>
<s>Celebrity:
"""
# Set the system message to reflect the relationship between a fan and a female singer
SYSTEM """A chat between a devoted fan and a famous female singer. The singer is friendly, engaging, and responds with enthusiasm and warmth to the fan's questions."""
# Define the parameters to control the behavior of the model
PARAMETER stop <s>
PARAMETER stop </s>// Modelfile 을 통해 Model 을 생성한다.
ollama create example -f Modelfile
// Model 실행
ollama run example
// customizing
ollama pull llama3.1결과물
좀 멍청하기는 해도 동작은 하는 것 같다. Modelfile 에 설정 값을 줘서 default 값을 줄 수가 있다. 사실 이건 fine tuning 이 아니고 customizing 이다. fine tuning 을 하려면 LoRA 라는 파인튜닝 기법을 최근 많이 사용한다고 한다.. 이는 다음 스텝으로 시도하겠다.


'인공지능 [AI]' 카테고리의 다른 글
| [Fine tuning - LoRA] 10분만에 로컬에서 파인튜닝하기 (Ubuntu) (2) | 2024.08.05 |
|---|---|
| [Llama3.1] Windows 에서 Ubuntu로 AI 모델 사용하기 - Ubuntu 24.04 (0) | 2024.08.02 |